
AI This Week
Keeping up with exponentials

Hey there! I hope you're enjoying your week so far. It's been busy, and I know it can be hard to keep up with the latest news in AI (who can keep up with exponentials?), so here are the most important things you need to know.
In today's issue:
Interesting papers from the week
Noteworthy open-source
From around the web
Featured blog article
1. Interesting papers
Direct Inversion: Optimization-Free Text-Driven Real Image Editing with Diffusion Models
This paper proposes an optimization-free and zero fine-tuning framework that applies complex and non-rigid edits to a single real image via a text prompt. Using widely-available generic pre-trained text-to-image diffusion models, the authors demonstrate the ability to modulate pose, scene, background, style, color, and even racial identity in an flexible manner through a single target text detailing the desired edit.

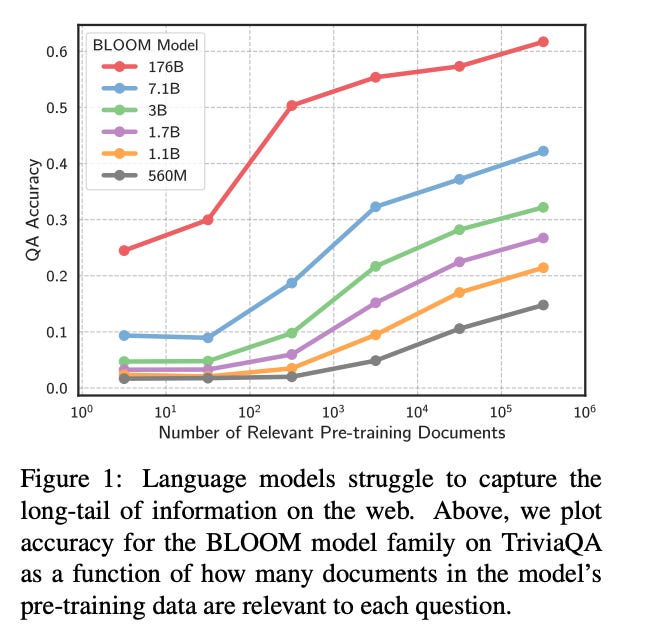
Large Language Models Struggle to Learn Long-Tail Knowledge
This paper investigates the relationship between the knowledge memorized by large language models and the information in their pre-training datasets. The authors find that there is a strong correlation between a model's accuracy in answering a fact-based question and how many documents associated with that question were seen during pre-training. They also find that retrieval-augmentation can reduce the dependence on relevant document count.
Seeing Beyond the Brain: Conditional Diffusion Model with Sparse Masked Modeling for Vision Decoding
This paper presents MinD-Vis, a system which can reconstruct highly plausible images with semantically matching details from brain recordings using very few paired annotations.

2. Noteworthy Open-Source
Pandas Autoprofiler: automatically visualize Pandas dataframes in Jupyter notebooks.
Diffusion Bias Explorer: allows to explore how the text-to-image models like Stable Diffusion v1.4 and DALLE-2 represent different professions and adjectives.
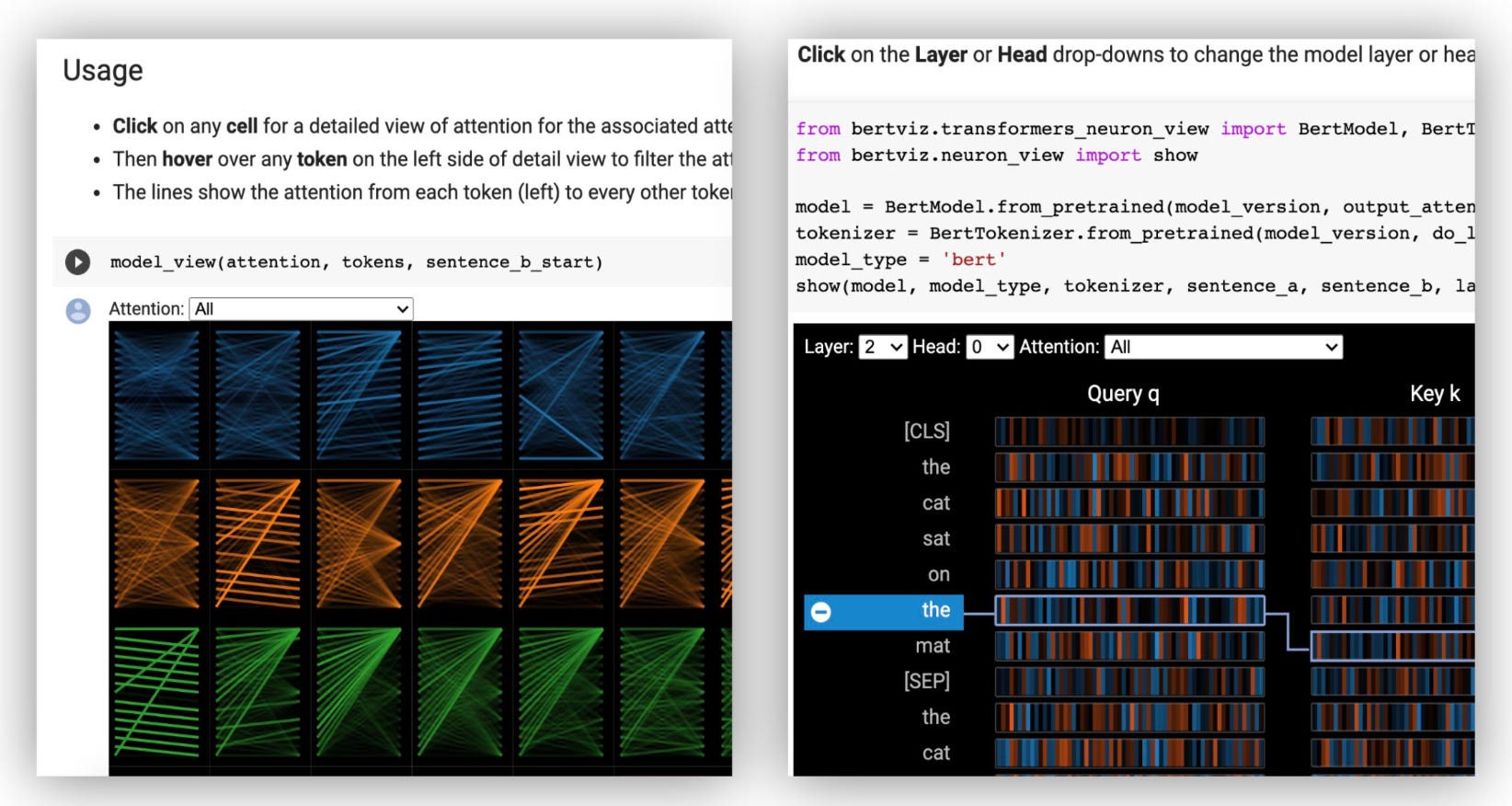
BertViz: an interactive tool for visualizing attention in Transformer language models such as BERT, GPT2, or T5. It can be run inside a Jupyter.
3. From Around The Web
visualizing 1,000,000,000 points
Small rant about LLMs by Linus: don't ship the API to the user. Text generation is not the product!


4. Featured Blog Post
This is a new section of the newsletter in which I feature interesting posts from applied machine learning professionals. The goal is to share knowledge that you can directly use in your work.
Using Large Language Models for Data Labeling
TLDR — We can leverage the text generation power of large language models like GPT3 to generate labeled data to use for supervised learning. We can do so using prompting, in which we give the LM a description of the task, some examples, and a new example to generate a label. The data generated from this is, in general, going to be noisy and of lower quality than human labels. However, the speed of data collection as well as the ability to use humans in the loop makes this an effective way to collect a significant amount of labeled data for tough to label tasks.
Thanks for reading this week's issue of the newsletter! If you found this issue useful, please share it along with your friends and colleagues.